When Java programmers talk about Web Services, they are often talking about Simple Object Access Protocol (SOAP). With JAX-RPC and JAXM libraries to build SOAP messages, released via the Sun Java Community Process (JCP), and the open-source Apache Axis project, SOAP is almost the reference implementation for Web Services. Web Services work by serializing the remote procedure call (RPC) into XML, then wrapping the XML in some more XML to specify message properties, such as the destination server URL, the SOAP version being used, etc. The server deserializes the XML into the appropriate method call, executes it, serializes the result back into XML, and wraps it in more XML and sends it back to the client via HTTP.
Older versions of Web Services (SOAP 1.1) used HTTP POST exclusively as the underlying protocol to send and recieve messages. This makes sense, because your calls can have Objects as method parameters, and these are easier to encode as XML in a POST than as parameters in a GET request. However, this restriction runs afoul of the HTTP specification, which says that one should use HTTP GET requests for calls which do not change the state of the server or have any side effects, and HTTP POST requests for calls that do. So read-only Web Service calls, such as getting a stock quote from a stock server, should not require me to use HTTP POST. Even if you don't mind bending the spec once in a while, there is a practical downside - for caching (and you will need caching if you have any significant traffic), you are limited to using a cache that resides within the server JVM, rather than an external cache such as Squid, which can be more appropriate sometimes. SOAP 1.2 addresses this issue and provides support for HTTP GET requests.
SOAP tends to be quite verbose, however, and consumes serious bandwidth. Lighter alternative implementations such as Caucho's Burlap or Hessian are adequate for most applications, with the added advantage of minimal (compared to SOAP) network overhead. However, neither Burlap nor Hessian supports HTTP GET requests. This article describes how to enable HTTP GET support for Burlap using the Spring Framework.
Axis 1.1 (with SOAP 1.1, which did not support HTTP GET requests) has a workaround which provides limited support for GETs, as this article explains. My objective was to do something similar for Burlap, so I could pass the method name and the arguments as request parameters.
To illustrate this, I created an API which exposes the following two methods. This API will live on both client and server.
1 2 3 4 | public interface IArticleService {
public Article getArticle(Long articleId);
public Comment[] getCommentsForArticle(Long articleId);
}
|
On the server side, there is a simple POJO service (called ArticleService) which implements the IArticleService interface. This POJO is injected into the BurlapServiceGetServiceExporter (described below) in the server's Spring configuration. This is what the server configuration looks like:
1 2 3 4 5 6 | <bean id="articleService" class="org.springchains.app.chains.remoting.server.ArticleService" />
<bean id="articleServiceExporter" class="org.springchains.framework.remoting.server.BurlapGetServiceExporter">
<property name="serviceInterface" value="org.springchains.app.chains.remoting.api.IArticleService" />
<property name="service" ref="articleService" />
</bean>
|
The BurlapGetServiceExporter is similar to the BurlapServiceExporter provided by Spring, except that it supports HTTP GET requests only. Its really a specialized Spring Controller object, and extends Spring's RemoteExporter, and overrides the setService() and handleRequest() methods. The handleRequest() method looks for the required parameters method (for method name to call), pn (the number of parameters), p0..pn (the parameter values), and t0..tn (parameter types). It then constructs objects out of the p/t pairs by calling t's String constructor, and invokes the method on the service using reflection. It then creates a Burlap response object and writes this into the request.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | public class BurlapGetServiceExporter extends RemoteExporter implements
Controller, InitializingBean {
private static final Log log = LogFactory.getLog(BurlapGetServiceExporter.class);
private Object service;
public BurlapGetServiceExporter() {
super();
}
public void setService(Object service) {
super.setService(service);
this.service = service; // we need this local copy, as service is private in superclass.
}
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response)
throws Exception {
String methodName = RequestUtils.getRequiredStringParameter(request, "method");
int numberOfParameters = RequestUtils.getRequiredIntParameter(request, "pn");
Object[] params = new Object[numberOfParameters];
for (int i = 0; i < numberOfParameters; i++) {
String type = RequestUtils.getRequiredStringParameter(request, "t" + i);
String param = RequestUtils.getRequiredStringParameter(request, "p" + i);
params[i] = ConstructorUtils.invokeConstructor(Class.forName(type), param);
}
Object result = MethodUtils.invokeMethod(service, methodName, params);
response.setContentType("text/xml");
BurlapOutput output = new BurlapOutput(response.getOutputStream());
output.startReply();
output.writeObject(result);
output.completeReply();
return null;
}
public void afterPropertiesSet() throws Exception {
checkService();
checkServiceInterface();
}
}
|
On the client side, the ArticleServiceHttpClient is provided the serviceUrl to make the RPC call. This is what the client configuration looks like:
1 2 3 | <bean id="articleServiceClient" class="org.springchains.app.chains.remoting.client.ArticleServiceHttpClient">
<property name="serviceUrl" value="http://localhost:8080/chains/article-service.html" />
</bean>
|
The actual ArticleServiceHttpClient is shown below. The methods just delegate to the IArticleService proxy that is created using the BurlapHttpGetFactory.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | public class ArticleServiceHttpClient implements IArticleService {
private static final Log log = LogFactory.getLog(ArticleServiceHttpClient.class);
private String serviceUrl;
public ArticleServiceHttpClient() {
super();
}
public void setServiceUrl(String serviceUrl) {
this.serviceUrl = serviceUrl;
}
public Article getArticle(Long articleId) {
return getProxy().getArticle(articleId);
}
public Comment[] getCommentsForArticle(Long articleId) {
return getProxy().getCommentsForArticle(articleId);
}
private IArticleService getProxy() {
log.debug("Creating IArticleService proxy with serviceUrl: " + serviceUrl);
BurlapHttpGetProxyFactory factory = new BurlapHttpGetProxyFactory();
return (IArticleService) factory.create(IArticleService.class, serviceUrl);
}
}
|
The BurlapHttpGetProxyFactory.create() method returns a BurlapHttpGetInvocationHandler (aka Proxy) as a simple JDK Proxy object for IArticleService. The BurlapHttpGetInvocationHandler.invoke() method serializes the method call into a HTTP GET request using the rules detailed above, and sends it off to the service URL. It then parses the response that the service returns back into the Object that the remote call is supposed to return. Here is the code for these classes.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | public class BurlapHttpGetProxyFactory {
public BurlapHttpGetProxyFactory() {
super();
}
public Object create(Class interfaceClass, String serviceUrl) {
return Proxy.newProxyInstance(
interfaceClass.getClassLoader(),
new Class[] {interfaceClass},
new BurlapHttpGetInvocationHandler(serviceUrl));
}
}
public class BurlapHttpGetInvocationHandler implements InvocationHandler {
private Log log = LogFactory.getLog(BurlapHttpGetInvocationHandler.class);
private String serviceUrl;
public BurlapHttpGetInvocationHandler(String serviceUrl) {
this.serviceUrl = serviceUrl;
}
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
HttpMethod httpMethod = null;
try {
HttpClient client = new HttpClient();
httpMethod = new GetMethod(buildUrl(serviceUrl, method, args));
int rc = client.executeMethod(httpMethod);
if (rc != HttpStatus.SC_OK) {
throw new Exception("GET Failed, HTTP Status:" + rc);
}
return parseResponse(httpMethod.getResponseBodyAsStream());
} finally {
if (httpMethod != null) {
httpMethod.releaseConnection();
}
}
}
private String buildUrl(String baseUrl, Method method, Object[] args) {
String methodName = method.getName();
Class[] types = method.getParameterTypes();
StringBuffer ubuf = new StringBuffer(baseUrl);
ubuf.append("?method=").append(methodName).
append("&pn=").append(args.length);
int i = 0;
for (Object arg : args) {
ubuf.append("&p").append(i).append("=").append(String.valueOf(arg)); ubuf.append("&t").append(i).append("=").append(types[i].getName());
}
log.debug("url=" + ubuf.toString());
return ubuf.toString();
}
/**
* Parse the Burlap XML response sent by the server into the equivalent
* object representation.
* @param response the response InputStream.
* @return the Object.
* @throws Throwable if a RuntimeException occurs.
*/
private Object parseResponse(InputStream response) throws Throwable {
BurlapInput istream = new BurlapInput(response);
istream.startReply();
Object obj = istream.readObject();
istream.completeReply();
return obj;
}
}
|
Application code to invoke the RPC calls on the client is identical to the code that one would normally use to call standard Burlap services with spring. Examples are shown below:
1 2 3 4 5 6 7 | ArticleServiceHttpClient client = (ArticleServiceHttpClient) ctx.getBean("articleServiceClient");
Article article = client.getArticle(new Long(1));
// ... do something with article ...
Comment[] comments = client.getCommentsForArticle(new Long(1));
for (Comment comment : comments) {
// ... do something with comments ...
}
|
As an added bonus, you can even invoke the service using your browser. Note that this worked for me on Firefox 1.0.7, but not on Firefox 1.5 or Microsoft IE 6, because the latter are more picky about namespace prefixes (the burlap portion in the burlap:reply element), and complain that the prefix is not mapped to a namespace. Hopefully, there is a simple browser workaround for this, please let me know if you know of one. Here are some screenshots of my browser with the XML responses to these two method calls.
 |
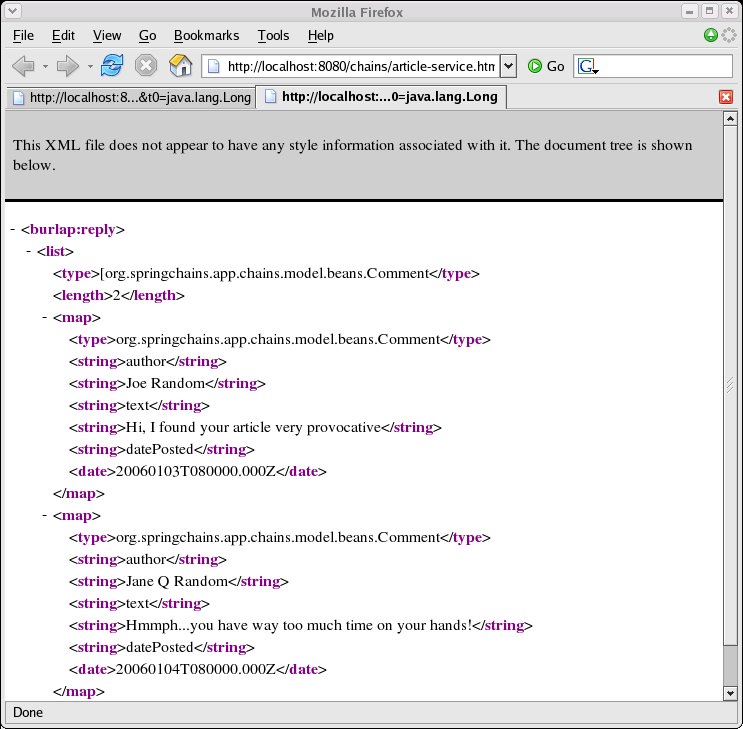 |
So there you have it, folks. A complete drop in replacement for accessing your Burlap services with HTTP GET requests where appropriate. Assuming you supply the client with a toolkit to access your service, application code to access your toolkit remains identical. The client toolkit will now use BurlapHttpGetProxyFactory to generate the proxy instead of the BurlapHttpProxyFactory provided by Spring. On the server, the Spring BurlapServiceExporter is replaced with the BurlapGetServiceExporter.
Of course, there are caveats to this approach. You need to make sure that your arguments must be objects which take a String constructor, so you will have to do some extra work if you want to pass parameters which are not primitive wrappers (Long, Integer, String, etc). This can be achieved by encoding these objects as JSON or JPList (written by yours truly) strings and parsing it back to the object on the server. You also need to consider the length restrictions of HTTP GET requests (512 bytes).















